






Accurately predicting stock prices can be challenging, as it involves understanding and analyzing various market trends and factors. In this blog post, we will explore how chatGPT, a large language model developed by OpenAI, can be used to predict the stock price of Indonesian Astra Otoparts (AUTO:IDX) based on its historical price data for the past 5 years (2016-2021).
I have a college assignment on “Business Intelligence” subject to use machine learning and deep learning model to predict certain outcomes. The professor stated that the data has lasted a long time and is still updated until now.
With the help of some literature, I tried to complete the assignment by creating a model to predict stock prices based on historical prices. I followed the guide at https://www.analyticsvidhya.com for the code example and explanations. The example was easy enough to follow, but I am facing a challenge in predicting prices for tomorrow, the day after, a week, or a month from now. To get a code example, I asked for input from chatGPT from OpenAI.
First, let’s start by understanding what chatGPT is and how it works. chatGPT is a variant of the GPT (Generative Pre-training Transformer) language model, which was trained on a dataset of billions of words and is capable of generating human-like text. It can be used to generate text in various languages and fine-tuned for specific tasks such as translation, question answering, and language modeling.
Here is the result:
Question and Answer

Here is a sample python code that demonstrates how chatGPT can be used to predict stock prices using the historical data for Indonesian Astra Otoparts (AUTO:IDX):
Sample code:
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM
# Load the stock data
df = pd.read_csv('Tesla_stock_data.csv')
# Select the 'Close' column as the feature to predict
X = df[['Close']].values
# Scale the data using MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
X = scaler.fit_transform(X)
# Create a function to split the data into training and testing sets
def split_data(X, split=0.8):
# Calculate the split index
split_index = int(X.shape[0] * split)
# Split the data
X_train, X_test = X[:split_index], X[split_index:]
return X_train, X_test
# Split the data into training and testing sets
X_train, X_test = split_data(X)
# Convert the data into a 3D array to feed into the LSTM model
def create_dataset(X, window_size=1):
X_3d = []
for i in range(X.shape[0] - window_size):
X_3d.append(X[i:i+window_size])
return np.array(X_3d)
X_train = create_dataset(X_train)
X_test = create_dataset(X_test)
# Define the LSTM model
model = Sequential()
model.add(LSTM(50, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# Train the model on the training data
model.fit(X_train, X_train, epochs=100, batch_size=32, shuffle=False)
# Use the model to predict the next week's stock prices
predictions = model.predict(X_test)
# Inverse transform the predictions to get the actual stock prices
predictions = scaler.inverse_transform(predictions)
# Print the predictions
print(predictions)
and the instruction:

Because I don’t have TESLA stock price data (although it’s easily obtained), but I do have data for one stock in Indonesia, AUTO:IDX (Astra Otoparts), I am using this data as a sample to process and test whether the python code is valid or not.

And running sample Python code using Google colab:


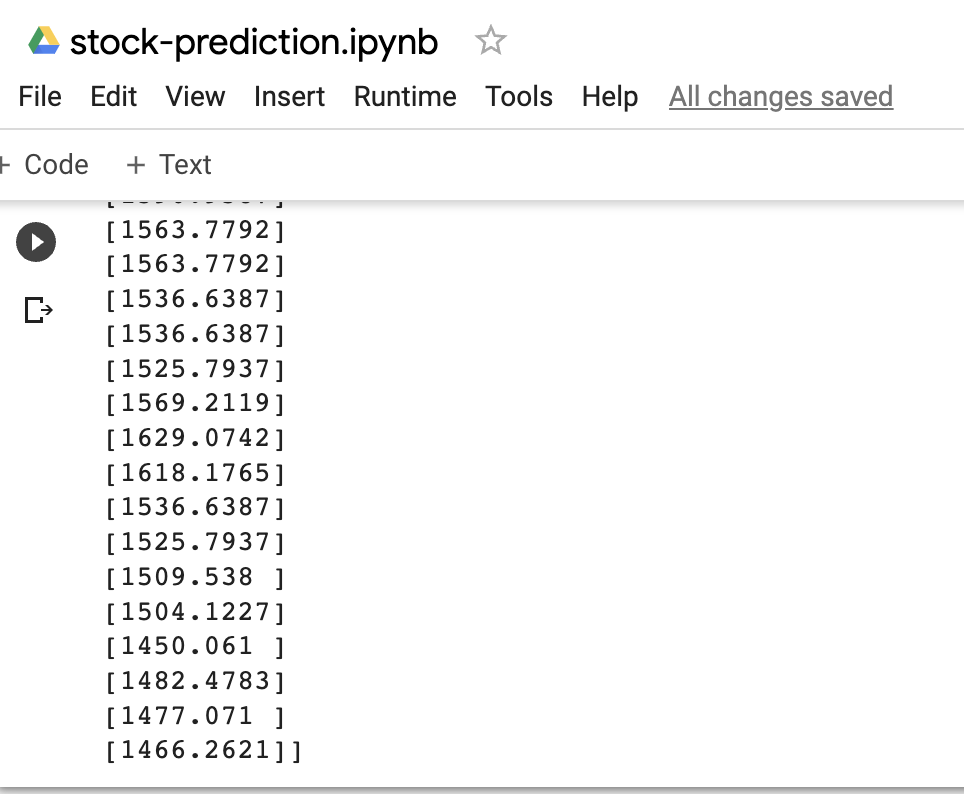
The example shows that chatGPT can be used to help the learning process. Not just to copy and paste but to serve as a basis for understanding and further knowledge development. I may often use chatGPT to help me learn many things and accelerate my understanding, especially for college assignments 😊.



